
The journal Psychological Science has published some odd research lately. There’s a fun back-and-forth unfolding between statistician Andrew Gelman and psychologist Jessica Tracy and her student Alec Beall, who published one of those pieces. Both sides make good points, and Gelman does overstep a bit, but ultimately Gelman makes the better case.
![]() [See the research (pdf), Gelman's original critique, a response by Beall & Tracy, and Gelman's rejoinder.]
[See the research (pdf), Gelman's original critique, a response by Beall & Tracy, and Gelman's rejoinder.]
Beall & Tracy wrote a research article on whether women at peak fertility dress to maximize their attractiveness. Given that prior research asserts that red might indicate fertility, the authors conducted an experiment: they ask 100 women on Mechanical Turk and 24 undergraduates about the participants’ latest menses, and observe the color of the women’s shirts. They find a statistically significant relationship (p=0.02, p=0.051 for the two samples) between women wearing red and women being at peak fertility.
Gelman posted a critique for Slate, where he asserts that “this paper provides essentially no evidence about the researchers’ hypotheses.” He points out that the researchers’ samples are not representative, that their measure of “peak fertility” may be flawed, and that participants may not accurately recall their last menstrual period.
Gelman’s larger critique, however, indicts the general practice of data analysis in many social sciences. He cites the “researcher degrees of freedom” in the Beall & Tracy piece, meaning that researchers have many choices in their research designs that may affect their outcomes. For example, Beall & Tracy chose to combine red and pink into a single category, to collect 100 Turkers and 24 undergraduate participants, to compare shirt color only, to compare red/pink to all other colors, to use days 6-14 as “peak fertility”1, and so forth.
At its most benign, these well-intentioned choices could result in false positive results. More nefariously, researchers could massage the research design, methods, or even rewrite their predetermined hypotheses, to get a publishable result.
Gelman isn’t wrong to point this out, though I find some parts of his criticism unsettling. As the authors write in their rebuttal, Gelman’s critique was published without consulting the authors. If Gelman aspired to clarify the research, he should have reached out to the authors with his comments before impugning their work in Slate. This goes beyond academic courtesy: the authors may have been able to answer some questions which would make the entire discussion more informative.
Some of Gelman’s critiques are also pedantic. Debates about measurement and sample representativeness, while important, are first-year graduate seminar fodder. His “researcher degrees of freedom” point lands a harder blow, though it seems to accuse the authors of subconsciously mining for statistical significance without any real evidence in this particular case.
So why is Gelman right?
Gelman points to a real concern in social scientific research, even if Beall & Tracy take the brunt of his criticism. Current practice heavily incentivizes scholars to find statistically significant results, but the requirements for publication and replication do not sufficiently disincentivize “mining” for significance stars.
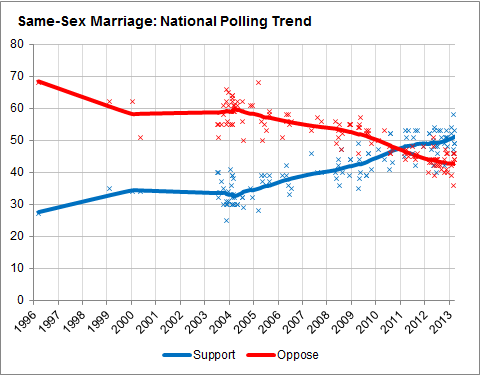
Psychological Science has published several weird pieces lately, including work relating physical strength to political attitudes that I criticized on this blog (Parts I, II). Gelman, too, has pointed to several of these curious studies. In each case, the claims far surpass the data mustered to support them.
With surprising claims, like the one made by Beall & Tracy, should come additional scrutiny. Think of this as a Bayesian updating issue. Radical claims are radical because I see little reason to believe them a priori, so my prior belief is pretty strong that the effect doesn’t exist. Compared to intuitive claims (do liberals tend to vote Democratic?), radical hypotheses should require much stronger evidence to overcome my prior belief.
This may seem too subjective, or too unfair to researchers like Beall & Tracy, but that’s science. A top journal should demand much stronger evidence than two small samples to support such a radical claim.
We should, as a field, also move toward preregistered research designs. Beall & Tracy may not have tweaked the designs or hypotheses to match their data, but this type of practice happens, and will will continue unless scholars are required to lock in their designs before collecting any data. Changing publication bias to accepting interesting questions and designs, instead of interesting results, would help too.
Gelman targeted Beall & Tracy when his true criticism points at social science publication writ large. That doesn’t mean, though, that he’s not correct. The Beall & Tracy work makes a big claim which it supports with small samples and few robustness checks.
It’s the research equivalent of a sexy stranger who turns out to have little personality.




 that represents “risk of death” in various occupations. Now let’s assume that nature defines some true function linking “risk of death” to wages, and the function is arbitrarily complicated:
that represents “risk of death” in various occupations. Now let’s assume that nature defines some true function linking “risk of death” to wages, and the function is arbitrarily complicated:}{1-x_i} + \epsilon_i")
 1, meaning that the limit from the left
1, meaning that the limit from the left  = \infty") . This comes from the denominator (since dividing by 0 is undefined), and could match some intuition about nobody accepting any reasonable wage for a risk
. This comes from the denominator (since dividing by 0 is undefined), and could match some intuition about nobody accepting any reasonable wage for a risk  1. The error term
1. The error term  we will assume to be normally distributed with expectation of zero.
we will assume to be normally distributed with expectation of zero.") , meaning uniformly distributed on the interval 0 (risk=0%) to 1 (risk=100%).
, meaning uniformly distributed on the interval 0 (risk=0%) to 1 (risk=100%). against y make it pretty obvious that the model misses the mark:
against y make it pretty obvious that the model misses the mark: , or really anywhere near it. The highest occupational risks
, or really anywhere near it. The highest occupational risks 
{kind=link}
{kind=link}
{kind=link}